
A few months ago, I had a conversation with several researchers from a prominent AI company in Toronto, and their company philosophy was that everybody should write production-grade code and even be able to deploy it. It made me think about a lot of stuff. About my team, about AI and managing the complexity of software engineering in general. AI teams are specifically interesting because they simultaneously require at least two disciplines: software/hardware engineering and scientific discovery.
So how does one work towards success and creating a cohesive team, or teams, of researchers and software engineers who work together and create great products? The product being either pure research in the context of an enterprise trying to gain a competitive edge in terms of intellectual property, or applied research geared more towards a commercial product in a given vertical, or a hybrid of both.
That was the challenge that we were facing three years ago. We as a team needed to create a software ecosystem for our financial client. It had several different components: a data ingestion system based on Kafka, ETL processes, feature engineering, a core process of discovering ML/Deep learning algorithms, and ultimately deploying them to production. It was a hybrid environment that required both scientific research and also creating a commercial product. It was interesting to observe the emerging intra-team patterns, which reminded me of my previous collaborations with scientists and software engineers. I found it interesting to carefully examine the hidden assumptions in the interactions of AI research and software engineering, and how management philosophy can affect these interactions, and ultimately the degree to which an organization’s goals can be achieved.
Competing vectors
Imagine you are a software/data engineer working with an AI researcher, or the other way around, depending on which role you prefer. As a software engineer, you move towards eliminating bugs and reducing the deficiencies in the design, if you have unknowns in your system, to a large extent you are exposed to risks. On the contrary as an AI researcher, you would move towards a new discovery, essentially you are moving towards what has been unknown till the moment of discovery. It doesn’t matter how novel it is, what matters is that it was previously unknown to everybody else. In other words: researchers move towards the unknown while software engineers move towards eliminating the unknown, Figure 1. I call this phenomenon the Competition of Unknowness Vectors (CUV). I have been thinking about CUV through three dimensions: system entropy, reward systems, collective vs individual goals, and interested to see where these vectors might converge or diverge.
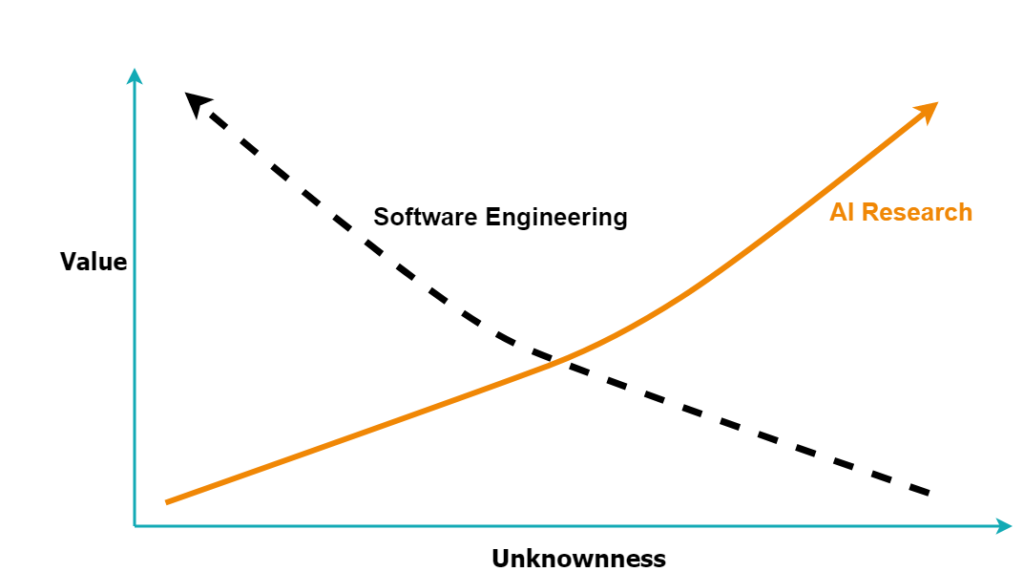
Figure 1: The Competition of Unknowness Vectors, as if there are two vectors, representing the efforts of each discipline, pointing to two different search spaces. Image by author.
System entropy
It would be interesting to look at unknownness through the lens of system entropy. The process of discovery in AI research, or any scientific research for that matter, seems to be accompanied by an increase in entropy in both the thought processes involved and the underlying workspaces. It is similar to energizing a beacon of thought and sending it to a high-dimensional space, looking for new discoveries. If your research beacon is not of high energy, it is unlikely that you can reach novel things. It seems one can’t do research without this intrinsic increase in entropy levels. How can one discover new frontiers of the unknown without a high dimensional search in the space of creativity? On the other hand, software engineering seeks to decrease entropy at the system level. This rise and fall of entropy can create friction in terms of goals, supporting systems, protocols, data pipelines, and the project’s operating budget, to name a few.
For example, early in our project, our researchers were constructing new models which constantly needed new streams of data, new transformation on those data, and new storage solutions for those data. Their speed of creativity exceeded what the data platforms were offering out of the box. It seems at this juncture a company might have two options, one is either to fall into the trap of converting researchers to part-time engineers who can also create their own ad hoc pipelines, which in my opinion is a self-defying activity as it leads to a significant reduction in the research capacity of the team. The second option is to come up with newer ways of supporting the researchers. The second option was ultimately the path we chose, which helped us to increase our research capacity without breaking the bank (I will get into more detail on how we scaled our team in the next post). The point I like to highlight here is how these two sub-systems, data pipelines and experimenting with different machine learning models, can be at odds in terms of increasing or decreasing system entropy. In addition to data pipelines, we saw the same pattern of rising and falling entropy, and hence the ensuing friction, in other sub-systems as well, for example in coding, testing, and designing custom simulations for ML models.
Reward systems
The reward systems for these two domains can be quite different. In science one is rewarded for making a discovery, the unboxing of the unknown. For example, the invention of the ADAM optimizer is a scientific achievement that made the training of deep models faster. While, let’s say, creating a high-performance data streaming pipeline that populates feature stores in real-time and also serves data to the production models, while very complex and extremely valuable, it is more of an engineering achievement than something that Science or NeurIPS would be interested to publish. I think the reward system is one of the major topics that a company needs to invest to clarify, as it impacts the ultimate goal of an enterprise and how it is balanced with the retention and the job satisfaction of both AI researchers and software engineers.

Photo by Aerial-motion/Shutterstock.com
Collective vs. individual goals
There are many ways that the unclarity of goals can emerge in a commercial AI company, but it seems that one of the most common ways is when it is attempted to simply replicate the management philosophy and the goals of academia. If one considers the competition of unknownness vectors, the reward systems, and system entropy, it can become a bit clearer why simply copying academia might not be the best idea for small and medium cap enterprises. Several different examples can be constructed to show this unsuitability.
For example, academia can afford almost boundless entropy in thought processes (and rightly so, because that’s what they are designed for, making new discoveries) while in a commercial enterprise unmitigated entropy might undermine the engineering efforts and intra-team efforts, hence the chances of productization.
Another example can be how progress is measured in an AI company. Early on in our project, we encountered a promising peer-reviewed paper in finance+ml, which had the theoretical protentional to solve some of our existing problems. However, to our surprise, we were unable to reproduce the promised results of the said paper. To address this issue, we as a team collaborated to create a simulation environment to test the chances of achieving the promised results of that paper. Through these probabilistic simulations, we discovered that the chance of achieving the published results of that paper was only 70%. This process, for us, was a success because of two reasons, first, it saved us from spending more time on that paper, and second that it revealed the hidden risks in that paper far exceeds what we could tolerate in a mission-critical environment. The success here, for us, was not necessarily writing a new scientific paper, it was to identify that a model is not aligned with the project’s goals.
A third example can be to examine the scale and texture of software engineering efforts required in academia vs an enterprise. In academia more often than not the software engineering efforts are done in silos, and interesting enough, these silos age very quickly and it is not expected from them to be interconnected and exchange data, because simply there is no urgent need for it, as the goals are not company-wide but rather individual-based. On the enterprise front, making these silos talk to each other, stay current, and serve multiple clients requires significant investment in software and data engineering efforts.
Thoughts forward
I think it is beneficial to examine the hidden assumptions which exist in AI enterprises, whether they lean more towards research or if they are a hybrid of research and product. And might help to ask questions which have far-reaching consequences: how the teams are structured, how progress is measured, how code is produced, how the agile iterations are done, who supports who and to what degree, and what is the definition of success: is it publishing more papers? or, as an example, becoming the leading AI provider in finance? Or even both? which then begs the question what are the structures, the teams, and the scaffoldings that a company is going to need to achieve the desired success. I am also interested to learn about your experiences and field observations either as an AI researcher, a software engineer, or a manager, please feel free to reach out via comments or messages.
Thanks for reading.
https://www.linkedin.com/in/atavakolie/
*This article was originally published in Towards Data Science
Header Photo by Valentin Valkov/Shutterstock.com
